
GMP模型的设计思想
前言
通过上一期的文章,我们知道了Go调度器的由来及作用:Go调度器用于合理分配goroutine(go的协程)到内核级线程中运行,实现高并发
概念
GMP模型是指Go调度器的内部模型结构,GMP三个字母是三个不同单词的简写:
- G: Goroutine, Go 语言中的协程。每个 G 代表一个要执行的协程,包含了该协程的栈空间、执行状态等信息。调度器通过管理和调度 G 来实现并发执行。
- M:Machine,操作系统(内核级)线程(OS thread)。M 是调度器和协程的中间层,负责将协程(G)绑定到线程(M)上执行。Go 调度器会根据系统的负载情况动态创建和销毁 M,以适应并发需求。每个 M 拥有自己的调用栈和一些状态信息,包括指令指针、堆栈指针等。 Go调度器最多可以创建 10000 个M。
- P: Processor,逻辑处理器。P 是调度器的实际执行者,负责执行 G。一个 P 在某个时刻只能执行一个 G,但可以执行多个 G。P 执行 G 的过程中,G 会占用 P 的上下文(上下文切换),直到执行完成或发生阻塞。一个 M 可以绑定到一个 P 上执行。
要注意的是:M是操作系统(内核级)线程的抽象,并不是真正的操作系统线程,每一个M会绑定一个操作系统线程,我们可以把它认为是一个代理人。
工作流程
一个GMP模型中,一个Goroutine从创建到执行的基本流程,我们可以拆分成下面几步:
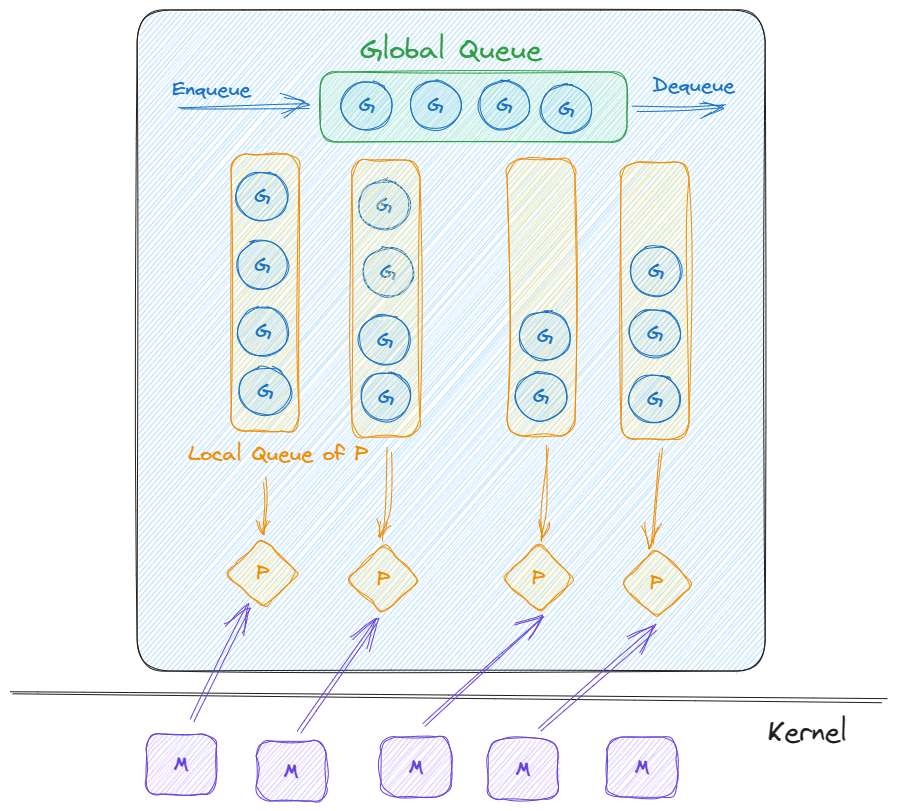
- 当一个Goroutine被创建时,它会被放入P的本地调度队列中(优先放入一个P的本地队列,P的队列都满了,则放入全局队列)。
- P会从本地调度队列中获取Goroutine,并将其绑定到一个可用的M上执行。
- 当一个Goroutine阻塞或需要等待某些资源时,P会将该Goroutine放回本地队列,并尝试从全局队列中获取新的可执行的Goroutine。
- 当某个M上的Goroutine执行完毕或发生阻塞时,P会将其放回本地队列,然后选择另一个Goroutine继续执行。
GOMAXPROCS
从上面的过程,我们可以知道,并行的Goroutine的数量其实取决于P的数量,而P的数量上限其实是可以使用的CPU的核心数。
我们可以通过调整环境变量GOMAXPROCS来设置要使用的最大CPU核心数内核线程数,这也是可以并行的M的数量(一个M绑定着真正的系统内核线程,M的数量可以很多,但是同时运行的数量必定不可能超过可使用的CPU数量),也就是P的最大数量。
一般情况下,GOMAXPROCS的默认值是机器上的CPU核心数。注意,这里因为超线程的技术,这里指的核心数不是物理核心数,而是虚拟核心数。比如常见的常常是四核八(CPU)线程,六核心十二(CPU)线程),那么它们对应的可以虚拟核心数和GOMAXPROCS默认值是8和12。同样的CPU线程和内核线程也是完全不一样的。
再次强调一下:M是操作系统(内核级)线程的抽象,并不是真正的操作系统线程,每一个M会绑定一个操作系统线程,用作代理以管理和调度Goroutine的执行。所以M既可以在用户态执行,也可以在内核态执行
调度器设计策略
M线程复用
Go调度器维护了一个线程池,其中包含了一组预先创建的工作线程。当需要执行goroutine时,调度器会选择一个空闲的工作线程(其实就是M),并将该goroutine绑定到该线程上,使其开始执行。当goroutine执行完毕或发生阻塞时,线程会被释放并重新放回线程池中,以便在需要时被复用。线程的复用机制有助于减少创建和销毁线程的开销。
抢占式调用
一般的协程(coroutine)是非抢占式调用的,但是Go调度器支持goroutinue抢占式调用。在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饥饿
交接 Hand Off
在Go调度器中,交接机制(hand off)指的是当一个线程(M)因为当前执行的goroutine阻塞时,该线程会释放绑定的P(处理器),将P转移到其他空闲的线程上执行
工作窃取 work stealing
当一个P的任务队列为空时,它可以从其他P的本地任务队列中“窃取”G来执行。但是这里有一个优先级问题,如果一个P的本地队列空了,是先从全局队列获取还是
先窃取其他P队列呢?本人在go1.20的源码src/runtime/proc.go中findRunnable()看到,调度器消费G其实是这样一个if判断顺序的:
获取当前M(操作系统线程)绑定的P(处理器)和判断初始化GC worker等等
判断全局的队列的是否有G而且当前调用次数是刚好是61的倍数则弹出一个G执行,保证公平
pp.schedtick%61 == 0 && sched.runqsize > 0- 判断本地有没有可以执行的G
- 判断全局有没有可以执行的G
- 判断网络轮询(network poll),安全检查,看看有没有等待或者阻塞的线程,有就先处理这个G
- 判断M是不是自旋状态和数量,开始work stealing
- 轮询网络任务,直到下一次的时间片
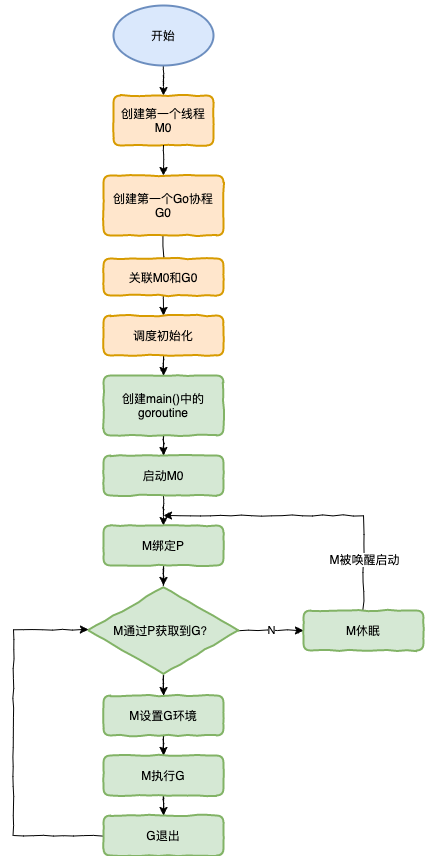
调度器的生命周期
M0
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
G0
G0是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
可视化GMP编程
有2种方式可以查看一个程序的GMP的数据
go tool trace
- 创建trace文件:
f,err:=os.Create("trace.out") - 启动trace:
trace.Start(f) - 正常编写业务代码
- 停止trace:
trace.Stop() go build后执行程序,就可以得到有记录的tarce.out- 利用trace工具可以生成一个网站查看
trace.out文件:go tool trace tarce.out
Debug trace
设置环境变量GODEBUG=schedtrace=1000后再执行程序可以进入Debug调试,也可以看到GMP的数据
以SCHED 0ms: gomaxprocs=12 idleprocs=10 threads=5 spinningthreads=1 needspinning=0 idlethreads=0 runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0]为例说明一下具体字段意思
| 字段 | 说明 |
|---|---|
SCHED |
调试信息输出标志 |
0ms |
即从程序启动到输出这行日志的时间 |
gomaxprocs |
P的数量最大值,默认和CPU虚拟核心一样(我的电脑是6核12线程,所以是12) |
idleprocs |
处于idle(空闲)状态的P的数量 |
threads |
M的数量 |
spinningthreads |
处于spinning(自旋)状态的M的数量 |
needspinning |
|
idlethreads |
处于空闲状态的M数量 |
runqueue |
全局队列中G的数量 |
[1 0 0 0 0 0 0 0 0 0 0 0] |
每一个P的本地序列存在的G的数量 |
参考链接
 wechat
wechat alipay
alipay